

Andrej Karpathy's full guide on how to use LLMs
You are just using 1% of LLMs capacity. Become a pro with this guide

Hey everyone, my name is Guillermo Flor and I’m an entrepreneur and Venture Capitalist.
I just came across with one of the most comprehensive explanations of how to use LLMS and couldn’t help myself to break it down for you.
Subscribe if you found it valuable and share with other founders/investors
PS: Check out resources you might valuable:
If you’d like to sponsor the Product Market Fit, email me at g@guillermoflor.com
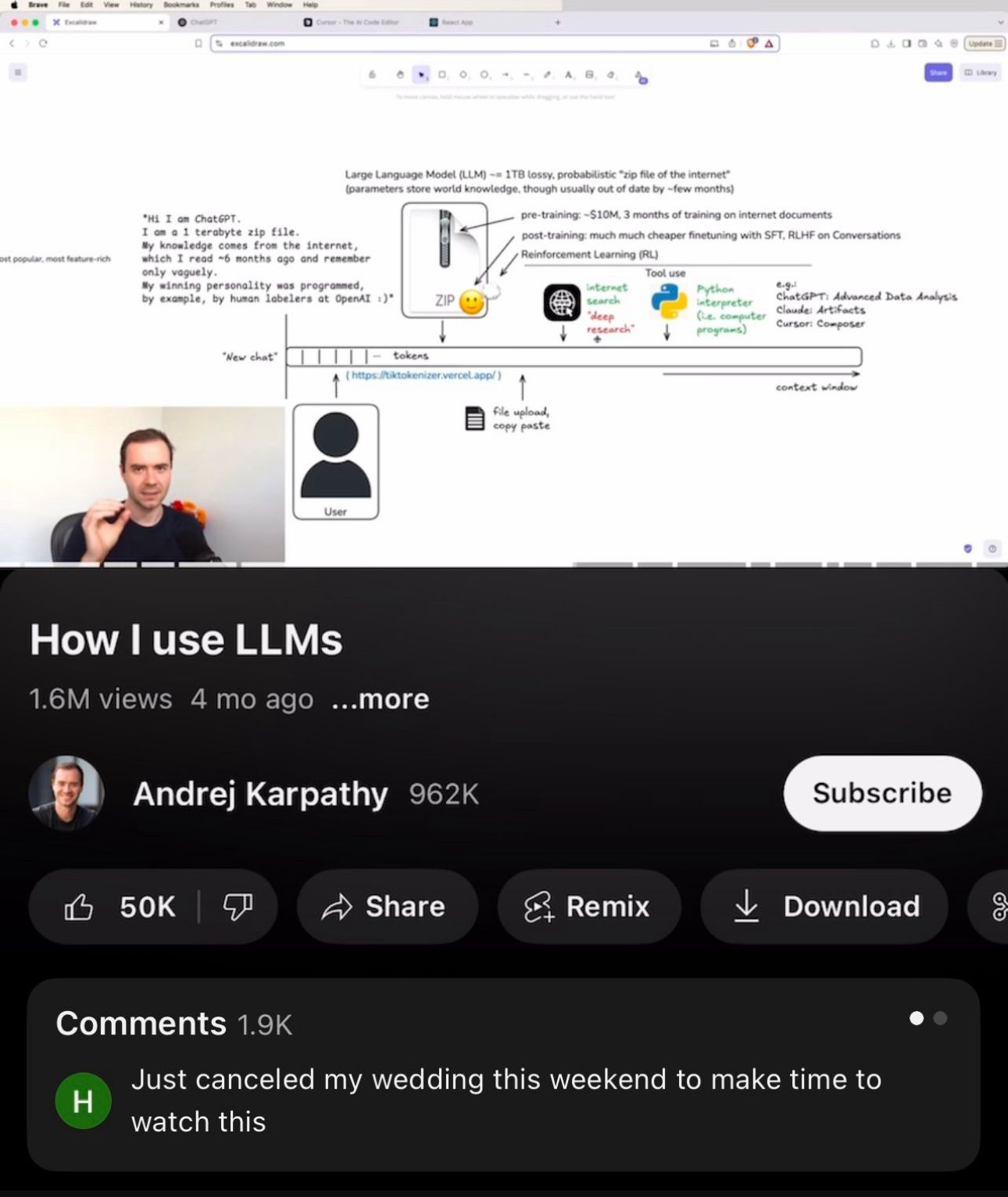
1: Overview of the Large Language Model Landscape
ChatGPT debuted on November 30, 2022, and reached 100 million active users by January 2023, making it the fastest-growing app ever.
This explosive growth attracted competitors: Google released Gemini in December 2023, integrating text, image, and video understanding; Meta launched Meta AI (powered by LLaMA 2) in April 2024 across Facebook and Instagram; Microsoft added GPT‑4–based Copilot into Office 365, boosting enterprise subscriptions by 15%.
Anthropic’s Claude raised $450 million to serve regulated sectors, and xAI’s Grok on X focuses on real-time social analytics. Regional solutions like Baidu’s DeepSeek and France’s Lichat address local language needs and data regulations.
Benchmarks such as Chatbot Arena’s ELO ratings and the Scale AI Leaderboard (MMLU, SuperGLUE, TruthfulQA) help compare strengths and weaknesses.

2. How LLMs Process and Remember Text
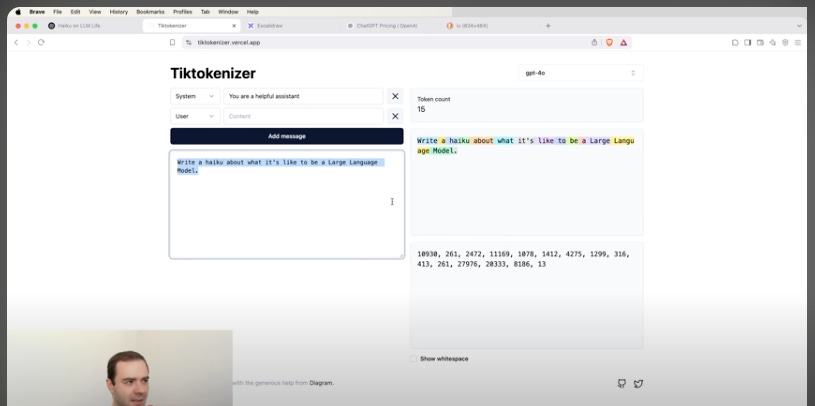
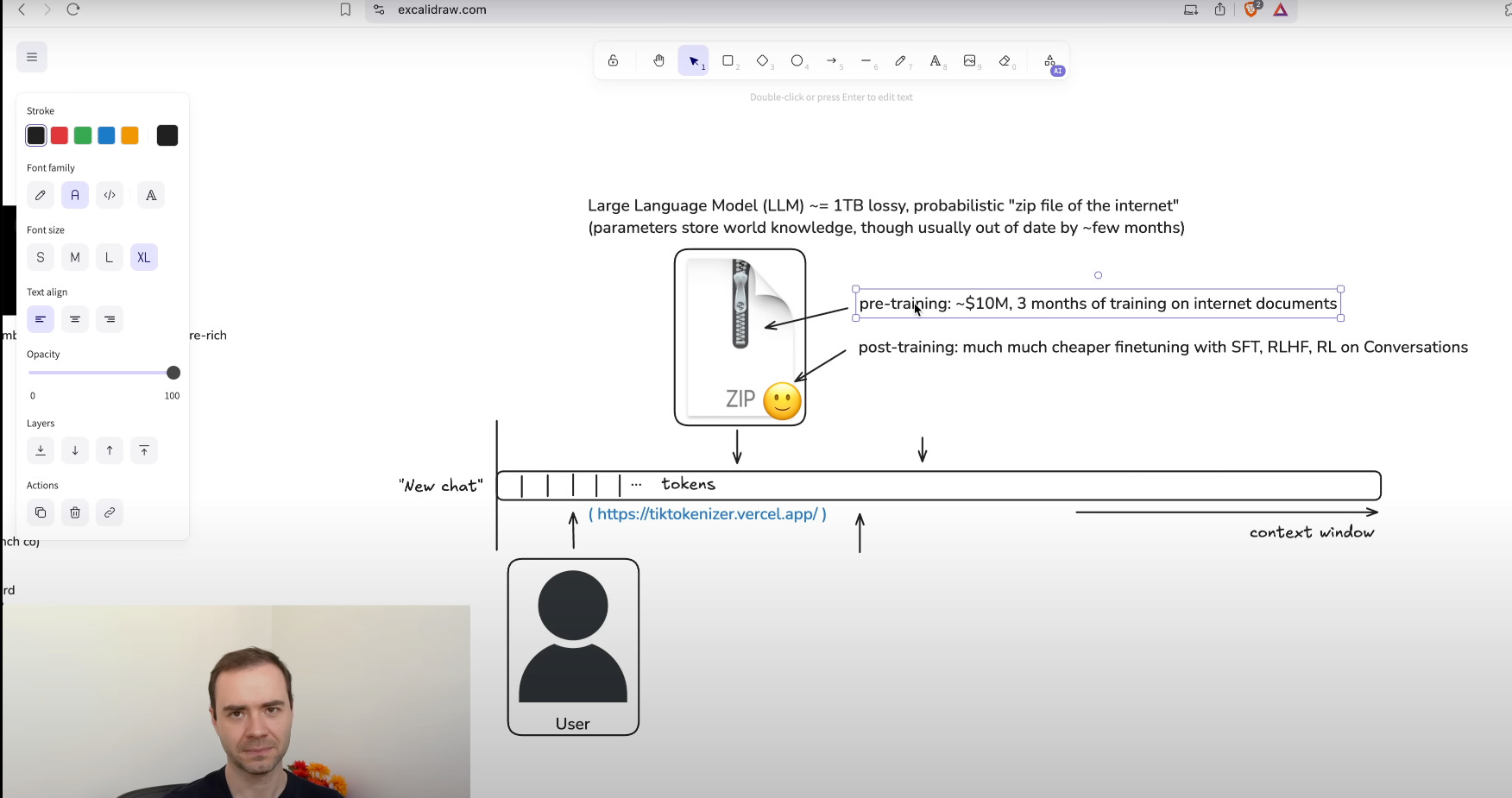
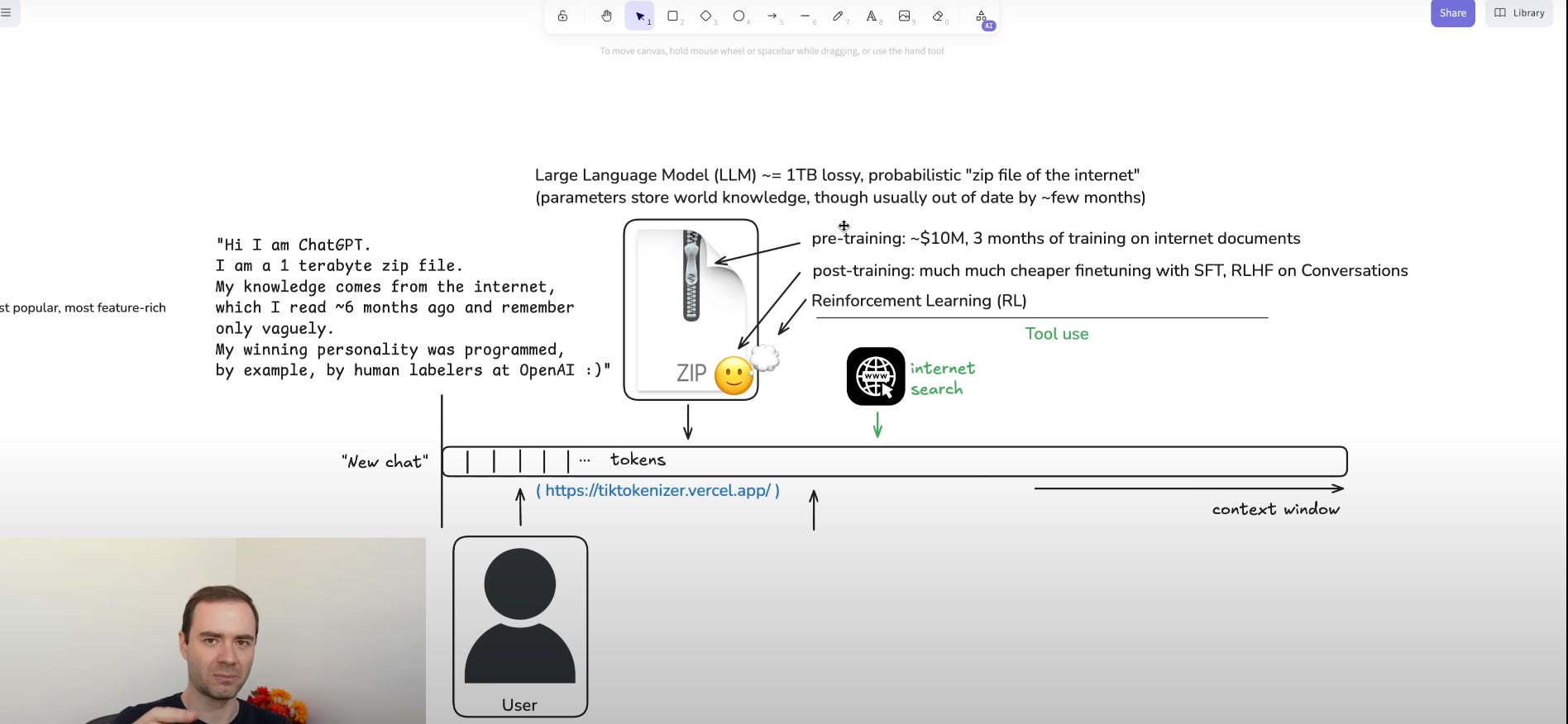
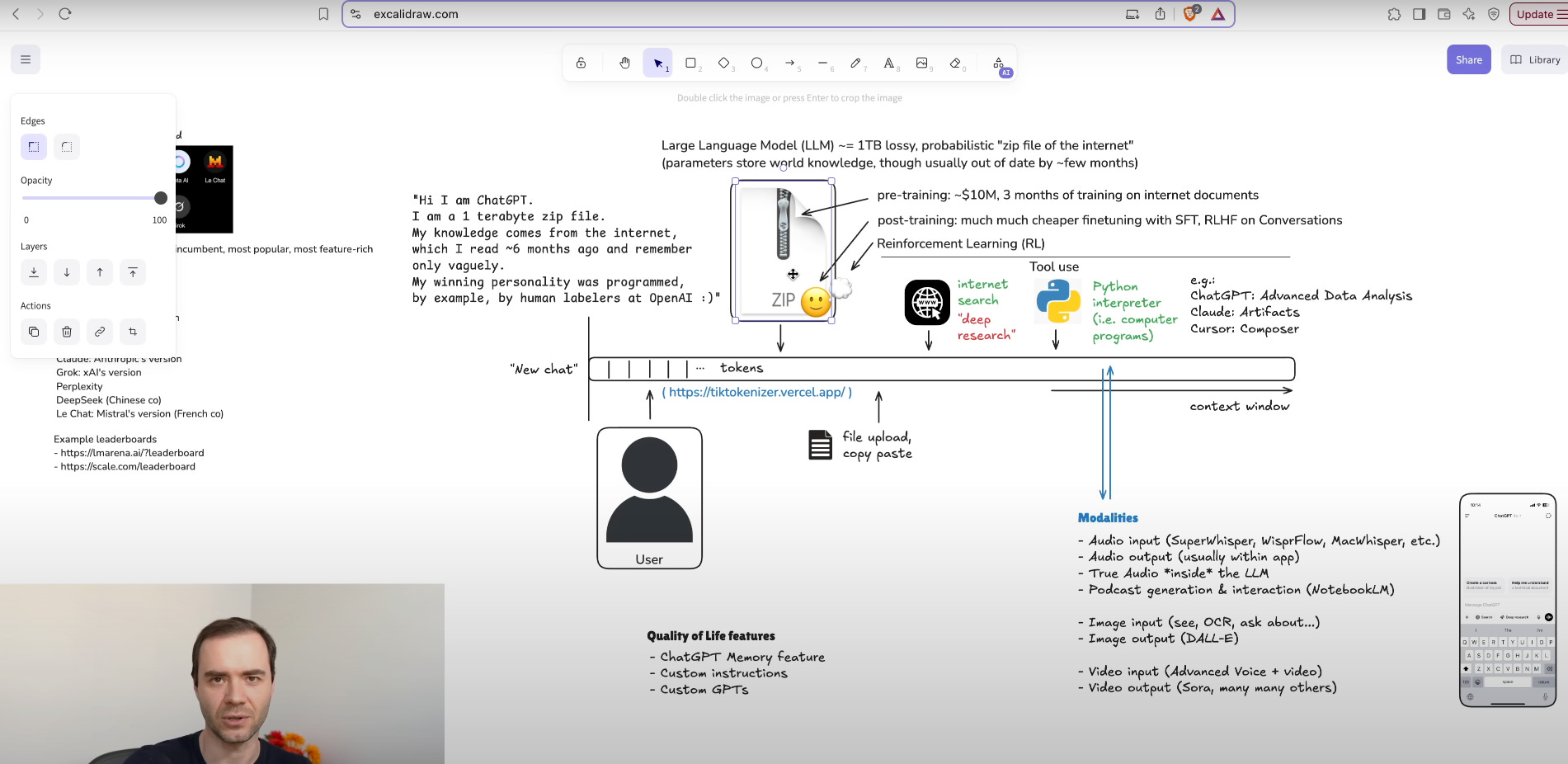
LLMs break text into tokens using Byte Pair Encoding (BPE). About 1 token equals 4 characters, so a paragraph of 500 characters becomes roughly 125 tokens. GPT‑4’s 200,000-token vocabulary and 32,000-token context window allow it to handle long conversations; smaller variants like GPT‑4o‑mini use an 8,192-token window. The model was pretrained on web pages, books, and code up to September 2021, encoding knowledge in 175 billion parameters. After that date, models need real-time tools or fine-tuning to stay current.
Special tokens mark user and assistant turns, and starting a new chat resets the context memory.
3: Basic LLM interactions examples
LLMs excel at both creative and factual tasks:
Creative: Prompting “Write a haiku about the experience of being an LLM” uses ~12 tokens and returns a three‑line poem in ~17 tokens.
Factual: Asking “How much caffeine is in one shot of Americano?” returns ~63 mg, matching USDA FoodData Central.
OpenAI’s internal benchmarks show >92% accuracy on general trivia, but accuracy drops under 80% on specialized domains (legal, medical, technical). Always verify high‑stakes information with authoritative sources.
4. Be aware of the model you're using, pricing tiers
Choosing the right model involves balancing performance and cost:
GPT‑4 (175 B): $0.03 per 1,000 input tokens, $0.06 per 1,000 output tokens on the Plus ($20/mo) plan (80 messages/3 hrs); Pro ($100/mo) removes limits.
GPT‑4o‑mini (400 M): Free; ~30% lower MMLU score; suitable for brainstorming and drafts.
Anthropic Claude 3 Sonnet: $0.02 per query; 128 K-token context—cost-effective for long documents.
Google Gemini Ultra: $0.04 per 1,000 characters; 2 M-character window for enterprise workloads.
Cost management tips:
Token budgeting: Summarize inputs, use concise prompts, and trim irrelevant context.
Model hybridization: Route low-stakes queries to cheaper models; reserve GPT‑4 for critical tasks.
Batching: Group related questions into one call to reuse context.
Monitoring: Use dashboards and alerts to track usage and spend.
Example: Summarizing a 2,000-word transcript (~5,000 tokens) on GPT‑4 costs $0.15 (input) + $0.30 (output). Switching to GPT‑4o‑mini cuts cost nearly to zero.
Why it matters: Cost control maximizes ROI and aligns LLM usage with budget and performance needs.

5. Thinking models and when to use them
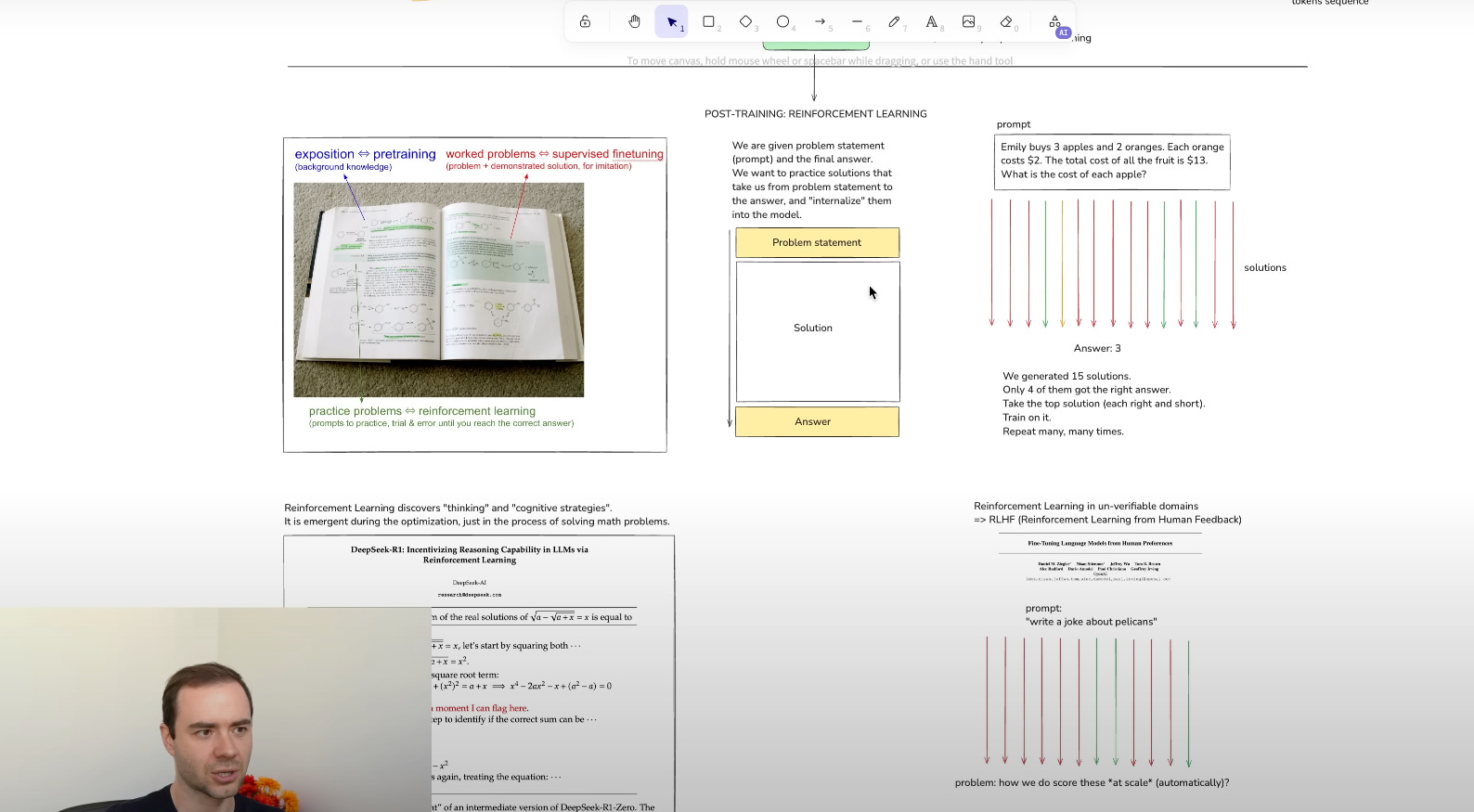
“Thinking” models incorporate reinforcement learning on chain‑of‑thought tasks, emitting <inner_thought> tokens that trace their reasoning steps. This method:
Improves accuracy: +40% on GSM8K arithmetic, +35% on logic puzzles.
Increases latency: 15–45 seconds per response vs. 3–5 seconds for standard modes.
Use thinking modes for debugging code, solving complex math problems, or multi‑step logic. Use standard modes for brainstorming, casual Q&A, and fast iteration.
6. Tool use: internet search
Combining LLMs with live search avoids outdated cutoffs and reduces hallucinations on dynamic topics
Retrieval-augmented generation adds real‑time data:
Embed
<search>query</search>tokens to call search APIs (Bing, Google).Fetch top 3 snippets (~200 tokens each), inject into context, and resume generation.
Adds ~400 tokens and ~1 second latency.
Ideal for queries about current events, product releases, or market data, ensuring outputs include citations and reflect up‑to‑date information.
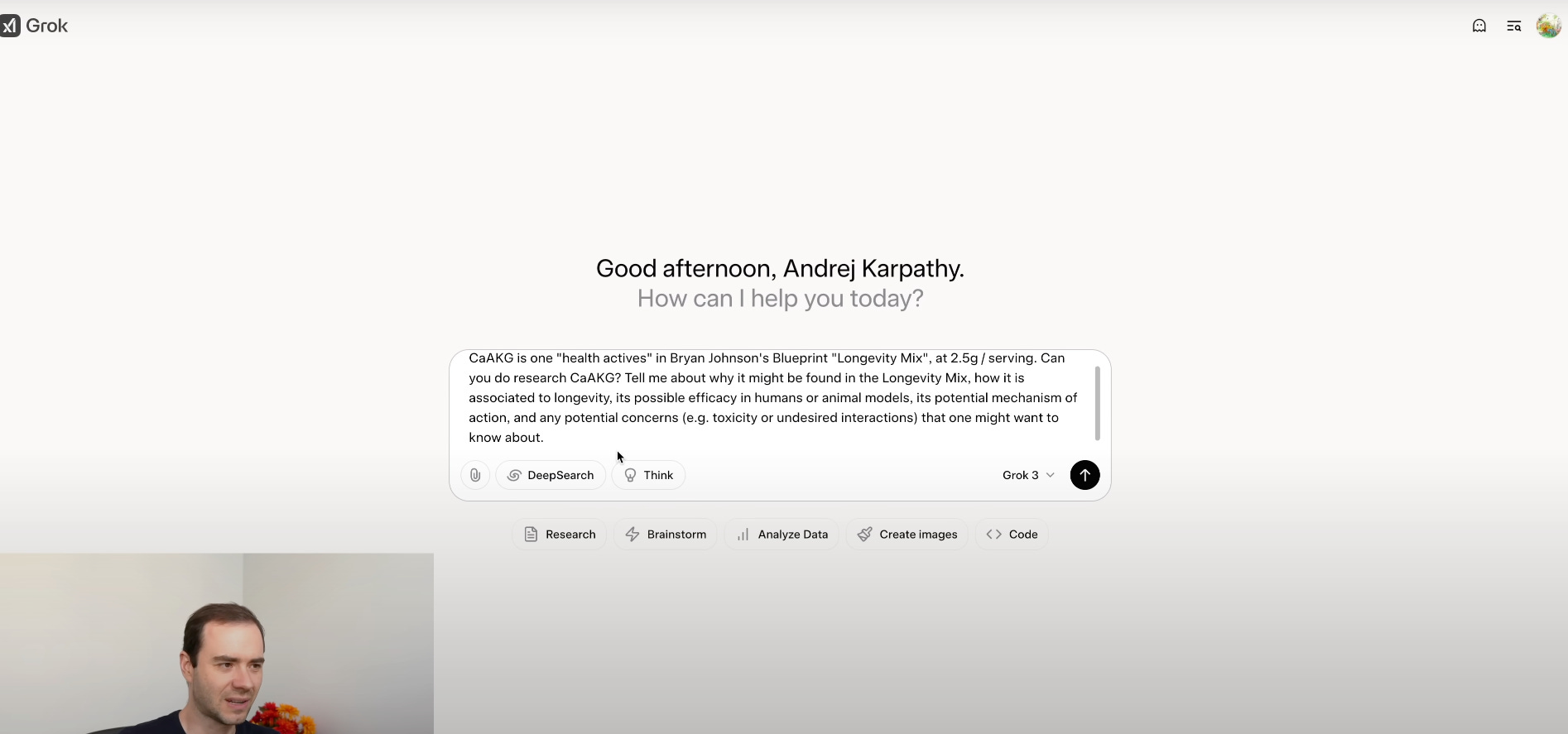
7. Tool use: deep research
When tackling complex topics, manually scanning dozens of papers can be overwhelming. Research APIs automate this process by providing structured access to academic literature:
Semantic Scholar API: Delivers paper metadata—titles, abstracts, author lists, citation counts, and topic tags—in JSON, simplifying batch analysis.
arXiv API: Offers preprint details—submission dates, PDF URLs, categories, and author affiliations—to stay ahead of emerging research.
PubMed API (Entrez): Focuses on life sciences and medical literature, returning abstracts, MeSH terms, journal information, and publication dates.
Step-by-step deep research workflow:
Define focused queries: Translate your research question into precise search terms (e.g., “transformer interpretability methods 2023”).
Fetch metadata: Pull abstracts, authors, citation networks, and funding details for the top 10–20 results.
Generate summaries: Prompt the model: “Summarize each paper’s key contributions, methodologies, and open questions.” Receive concise 2–3 bullet overviews per paper.
Analyze trends: Aggregate metrics (publication year, citation count) to spot high-impact works and trending topics over time.
Explore connections: Use embeddings or citation graphs to cluster related papers and identify foundational studies and follow-up research.
Example in practice:
Transformer interpretability survey: Use arXiv API to retrieve the 15 most-cited 2023 papers. Summarize each abstract, compare approaches (attention visualization vs. probing tasks), and highlight remaining challenges like model-agnostic interpretability.
Key considerations:
API limits: Most services cap requests (1,000–5,000 per day); implement batching and local caching to avoid disruptions.
Access rights: Verify open-access status or institutional subscriptions for full-text retrieval.
Coverage gaps: Complement with specialized databases (e.g., IEEE Xplore for engineering, ACL Anthology for NLP) to ensure comprehensive literature coverage.
8. File uploads, adding documents to context
Uploading your own documents transforms LLMs into personalized assistants that understand your specific content.
Supported formats & size limits: Platforms like ChatGPT ADA, Google Gemini Advanced, and Claude Pro accept PDFs, DOCXs, and TXTs up to 50 MB (roughly 100–200 pages).
Chunking & indexing: The system breaks documents into 2,048-token segments, then creates vector embeddings to index each chunk for semantic search.
Interactive querying: Ask precise questions such as “Summarize the methodology in Section 4.2” or “Extract the financial table on page 15.” The model retrieves and synthesizes relevant chunks in under 3 seconds.
Context-aware follow-ups: After an initial summary, you can ask deeper questions—“Compare the results of Experiment A and B” or “What were the authors’ stated limitations?”—and the model maintains context across queries.
Data extraction & export: Advanced Data Analysis (ADA) can parse tables into pandas DataFrames. For example, upload a sales report PDF and prompt “Convert the quarterly sales table to a DataFrame.” The model runs code that returns a DataFrame for immediate analysis or plotting.
Real-world scenario: A consulting team uploads a 150-page client report in DOCX format. They query, “What are the top three strategic recommendations?” The model scans relevant sections, summarizes key points, and generates a bullet-list. Follow-up: “Draft an executive summary based on these recommendations.” The assistant composes a concise two-paragraph executive brief.
Tips for effective use:
Clean document formatting: Ensure headings and tables are machine-readable to improve chunk alignment.
Use section references: Mention specific chapter or section titles in prompts for precise retrieval.
Manage context length: For very long documents, focus on one chapter at a time to avoid overwhelming the context window.
9. Tool use: python interpreter, messiness of the ecosystem
LLM platforms like ChatGPT Advanced Data Analysis (ADA) provide an embedded Python environment to run code alongside your conversation.
Environment setup: ADA uses Python 3.10 with preinstalled libraries like pandas 1.5.3 and matplotlib 3.7.1. You write code as part of your prompt or in code blocks.
Typical workflow:
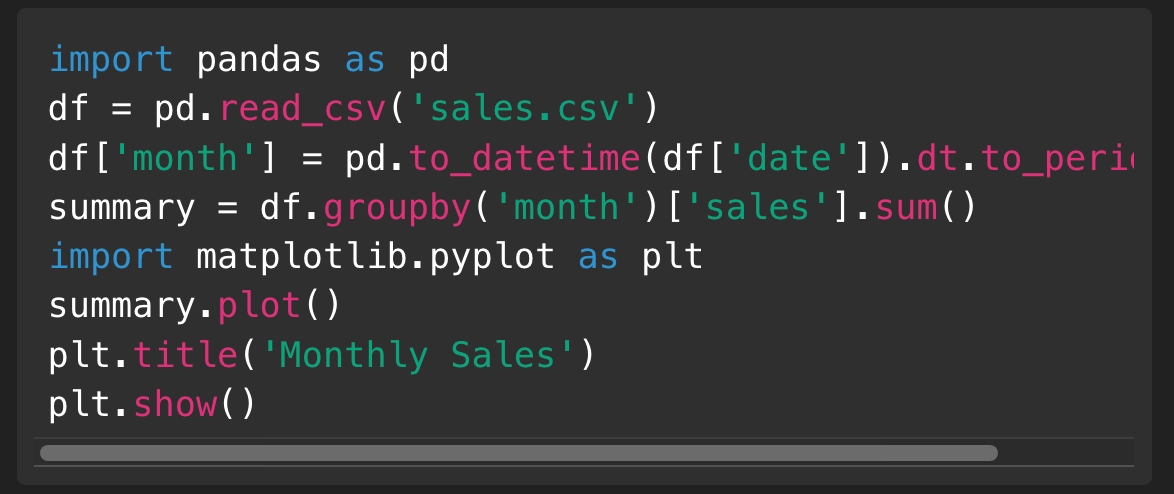
Load data: Use
df = pd.read_csv('data.csv')to import CSV files you’ve uploaded.Process data: Apply DataFrame operations (
df.groupby('category').sum()) to summarize or transform data.Visualize: Create plots with
plt.plot(df['date'], df['value'])andplt.show()to embed charts directly in the chat.
Handling errors: If a library is missing, ADA suggests a pip install command (e.g.,
!pip install seaborn) and reruns the code. Occasional environment inconsistencies (version mismatches or path issues) are resolved through these prompts.Example session:
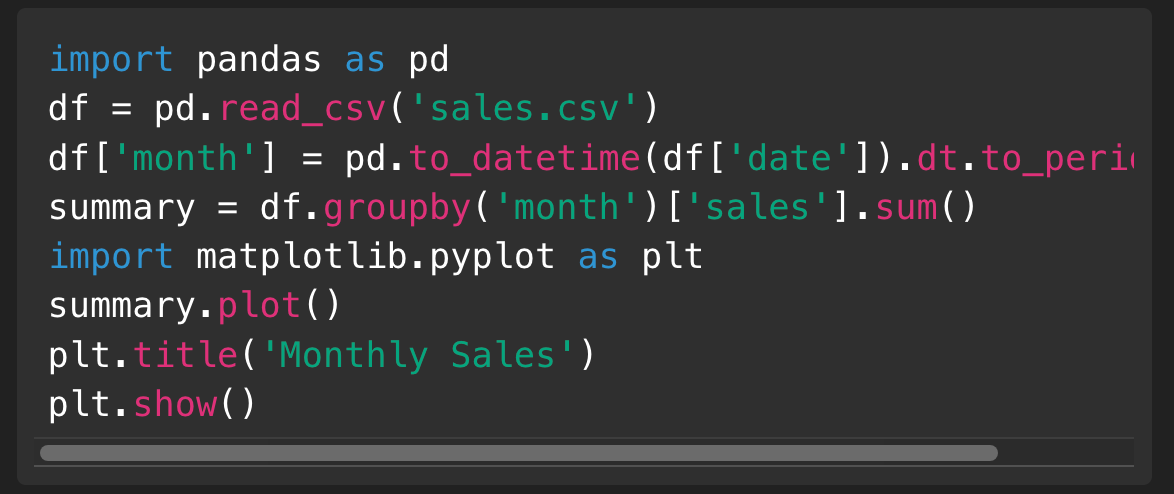
Prompt: “I’ve uploaded sales.csv. Load it and show total sales by month.”
Model code:
Result: A line chart appears, and the assistant provides a code snippet you can reuse.
Ecosystem quirks: Different LLM-based IDEs may use varying Python versions or library sets. Always check the environment details in platform documentation and adapt code accordingly.
10. ChatGPT Advanced Data Analysis, figures, plots
Automated charting bridges the gap between data and decision-making.
Use prompts like “Plot revenue by region over time” to generate Matplotlib code and visuals in ~2 s. Charts export as PNG or SVG, ready for reports or dashboards.
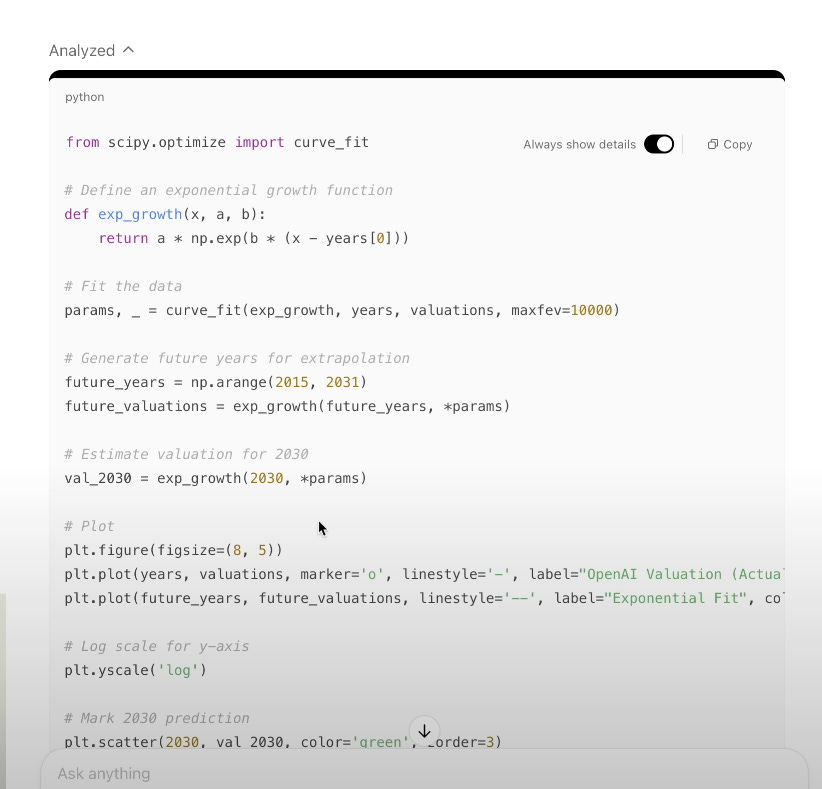
11. Claude Artifacts, apps, diagrams
Anthropic’s Claude offers built-in visual tools that turn text descriptions into diagrams and interactive artifacts.
Diagram generation: Describe a system or process in plain language. Claude uses Mermaid.js under the hood to render UML class diagrams, flowcharts, sequence diagrams, or mind maps within 2–4 seconds.
Interactive editing: After the initial render, ask for adjustments—"Add a database box connected to the API layer" or "Change this arrow to a dashed line to indicate optional flow." Claude updates the diagram live.
Export formats: Download diagrams as SVG or PNG, or copy the Mermaid.js code for integration into documentation or web pages.
Use case example: When outlining a microservice architecture, prompt:
"Draw a flowchart with a user interface, API gateway, authentication service, database, and external third-party API."
Claude returns a clear flowchart. Follow-up: "Highlight the authentication path in red and label it 'Auth Flow'."
Artifact library: Some Claude integrations provide a sidebar with reusable components—shapes, connectors, icons—that can be dragged into diagrams by referencing their names (e.g., "Add a Redis cache icon between API and database").
Tips for best results:
Use consistent naming: refer to components by the exact label used in previous instructions.
Break complex systems into smaller diagrams and then integrate them.
Preview Mermaid.js code to fine-tune styling or integrate with static site generators.
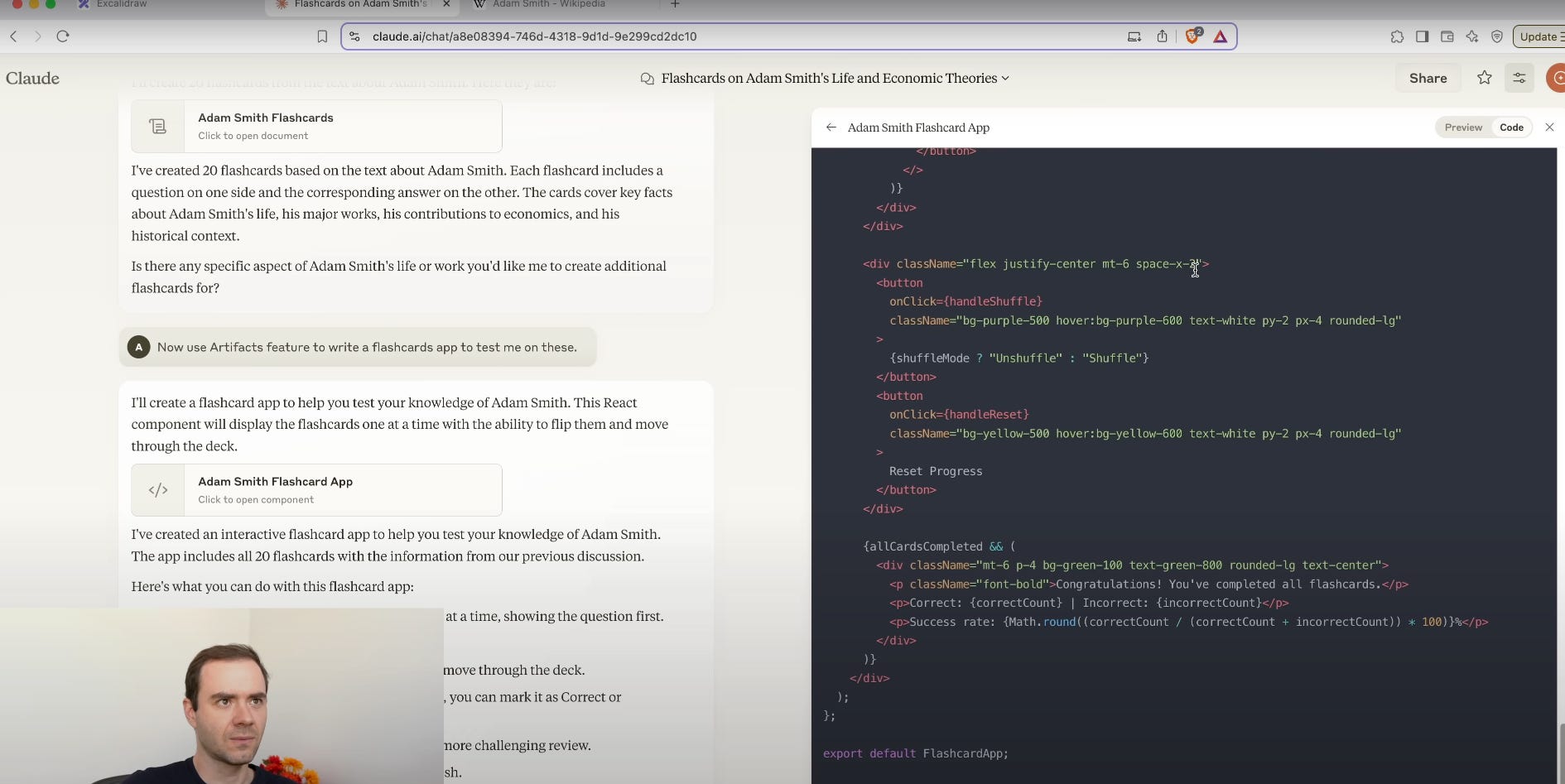
12. Claude Artifacts, apps, diagrams
Anthropic’s Claude offers built-in visual tools that turn text descriptions into diagrams and interactive artifacts.
Diagram generation: Describe a system or process in plain language. Claude uses Mermaid.js under the hood to render UML class diagrams, flowcharts, sequence diagrams, or mind maps within 2–4 seconds.
Interactive editing: After the initial render, ask for adjustments—"Add a database box connected to the API layer" or "Change this arrow to a dashed line to indicate optional flow." Claude updates the diagram live.
Export formats: Download diagrams as SVG or PNG, or copy the Mermaid.js code for integration into documentation or web pages.
Use case example: When outlining a microservice architecture, prompt:
"Draw a flowchart with a user interface, API gateway, authentication service, database, and external third-party API."
Claude returns a clear flowchart. Follow-up: "Highlight the authentication path in red and label it 'Auth Flow'."
Artifact library: Some Claude integrations provide a sidebar with reusable components—shapes, connectors, icons—that can be dragged into diagrams by referencing their names (e.g., "Add a Redis cache icon between API and database").
Tips for best results:
Use consistent naming: refer to components by the exact label used in previous instructions.
Break complex systems into smaller diagrams and then integrate them.
Preview Mermaid.js code to fine-tune styling or integrate with static site generators.
13. Audio (Speech) Input/Output
Adding audio I/O turns text-based models into voice assistants, useful for accessibility, multitasking, and natural conversations.
Automatic Speech Recognition (ASR):
Whisper-based models transcribe spoken input into text with ~99.1% accuracy on clear audio.
Supported audio formats: WAV, MP3, Ogg.
Typical latency: 500–1,000 ms for a 30-second clip.
Text-to-Speech (TTS):
Engines like Tacotron2 and WaveGlow convert text responses into natural-sounding audio in <200 ms per utterance.
Customization options: select voice style, adjust speaking rate and pitch.
Output formats: MP3 and WAV for easy integration.
Interactive usage flow:
Speak or upload an audio clip directly in the chat interface.
ASR transcribes the speech; the LLM processes the text as a prompt.
The model’s text reply is sent to the TTS engine, which generates spoken output.
Example scenario:
While driving, ask “What’s the weather in San Francisco?”
ASR captures the question, the LLM responds, and TTS reads back “San Francisco is currently 65°F and partly cloudy.”
Improving reliability:
Record in a quiet environment and use a quality microphone to reduce background noise.
Enable noise suppression features in the UI or pre-recording tools.
Include punctuation cues verbally (e.g., “comma,” “period”) if supported by ASR for more accurate transcription.
Advanced features:
Custom vocabularies: Add specialized terms (medical, legal) to improve domain-specific transcription.
Voice cloning: Some platforms allow uploading a voice sample to mimic a consistent speaker tone.
Real-time streaming: Continuous audio capture and transcription for interactive dialogues.
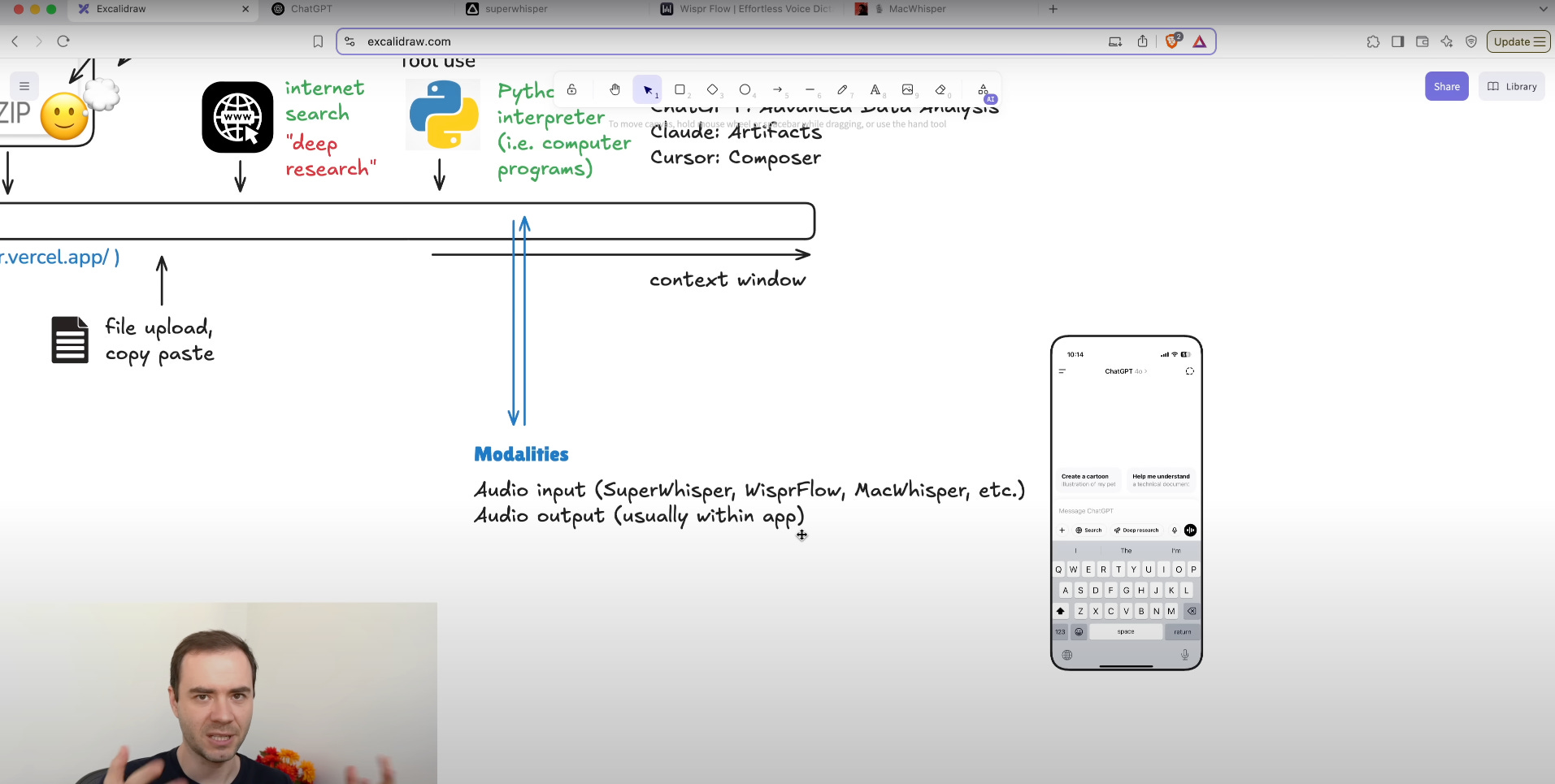
14. Advanced Voice Mode aka true audio inside the model
Advanced Voice Mode integrates ASR and TTS directly within the LLM’s inference pipeline, reducing dependencies on external services and minimizing latency.
On-device acceleration: Models employ specialized hardware (EdgeTPU, Neural Engines) to run ASR and TTS layers locally, achieving <80 ms latency end-to-end rather than routing audio through remote servers.
Seamless audio loop: Speech input is processed by onboard ASR, then the LLM generates a response, and onboard TTS immediately renders audio without context-switching or additional API calls.
Real-time translation: Audio streams can be piped through multilingual translation layers; for example, speak in English and receive French audio output in near real time.
Continuous conversation: Advanced mode supports streaming audio I/O—users can speak and hear the assistant’s reply in a fluid back-and-forth, similar to a phone call.
Use case example: In noisy factories or remote fieldwork, an engineer can issue voice commands to the assistant and receive immediate, spoken instructions for troubleshooting equipment without relying on internet connectivity.
Customization: Developers can fine-tune ASR and TTS models on specific accents or terminologies (medical, industrial) to improve recognition and synthesis accuracy.
Best practices:
Ensure compatible hardware acceleration is available (e.g., EdgeTPU, DSPs) on user devices.
Optimize microphone and speaker configurations to maintain audio quality.
Preload domain-specific language packs for specialized vocabulary support.

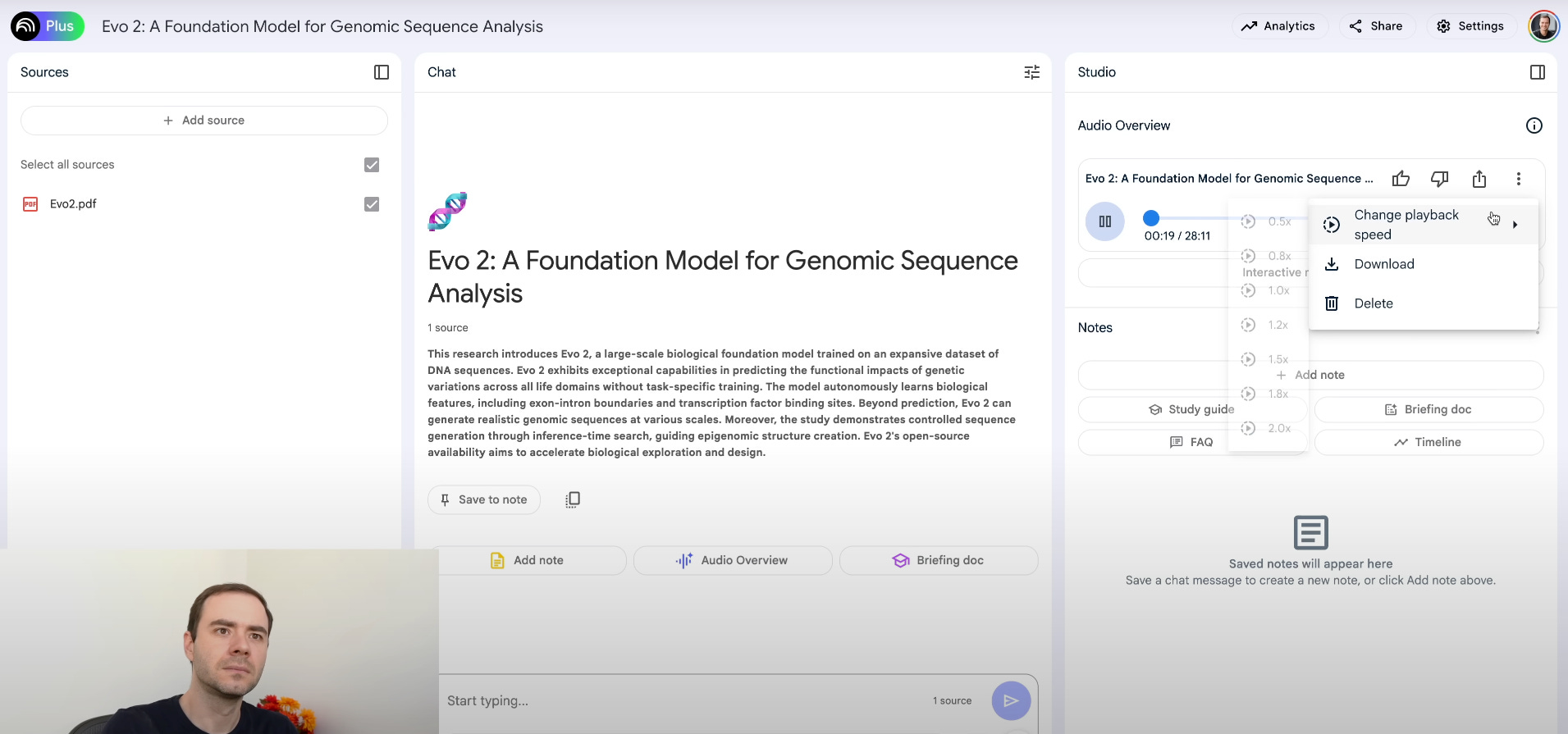
15. NotebookLM, podcast generation
NotebookLM is designed for deep engagement with long-form documents, combining Q&A, summary, and creative content generation in one tool.
Document ingestion: Upload lecture notes, research papers, or meeting transcripts (up to 10,000 characters per query). NotebookLM organizes content by sections, headings, and bullet points for efficient access.
Q&A over notebooks: Ask targeted questions such as "What are the three main hypotheses in Chapter 2?" or "Explain the experimental setup described in Section 4." The model locates relevant passages and provides concise answers in <1 s.
Structured summaries: Prompt "Summarize the methodology and key findings of this notebook" to receive a 150–200 word overview, complete with numbered lists and emphasis on critical details.
Podcast script generation: Provide a topic outline (e.g., "AI ethics, bias mitigation, future directions") and ask "Draft a podcast episode script." NotebookLM outputs:
Episode title and intro: Captures listener attention.
Segmented content: Interview questions, expert commentary prompts, and transitions.
Show notes: Bullet-point takeaways and resource links.
Closing remarks: Summarizes the episode and call to action.
Real-world scenario: An academic team uploads their latest research draft and asks, "Create a 5-minute podcast script introducing our work to non-technical audiences." In seconds, NotebookLM produces a formatted script with an engaging narrative, ready for recording.
Tips for effective use:
Organize source documents: Use clear headings and consistent formatting to improve navigation.
Specify audience: Mention the target listener (students, executives, general public) to tailor tone and complexity.
Iterate prompts: Refine script drafts by asking for shorter intros, additional examples, or alternative conclusions.
Why it matters: NotebookLM streamlines both deep-dive research and creative content production, bridging the gap between complex documents and accessible formats.
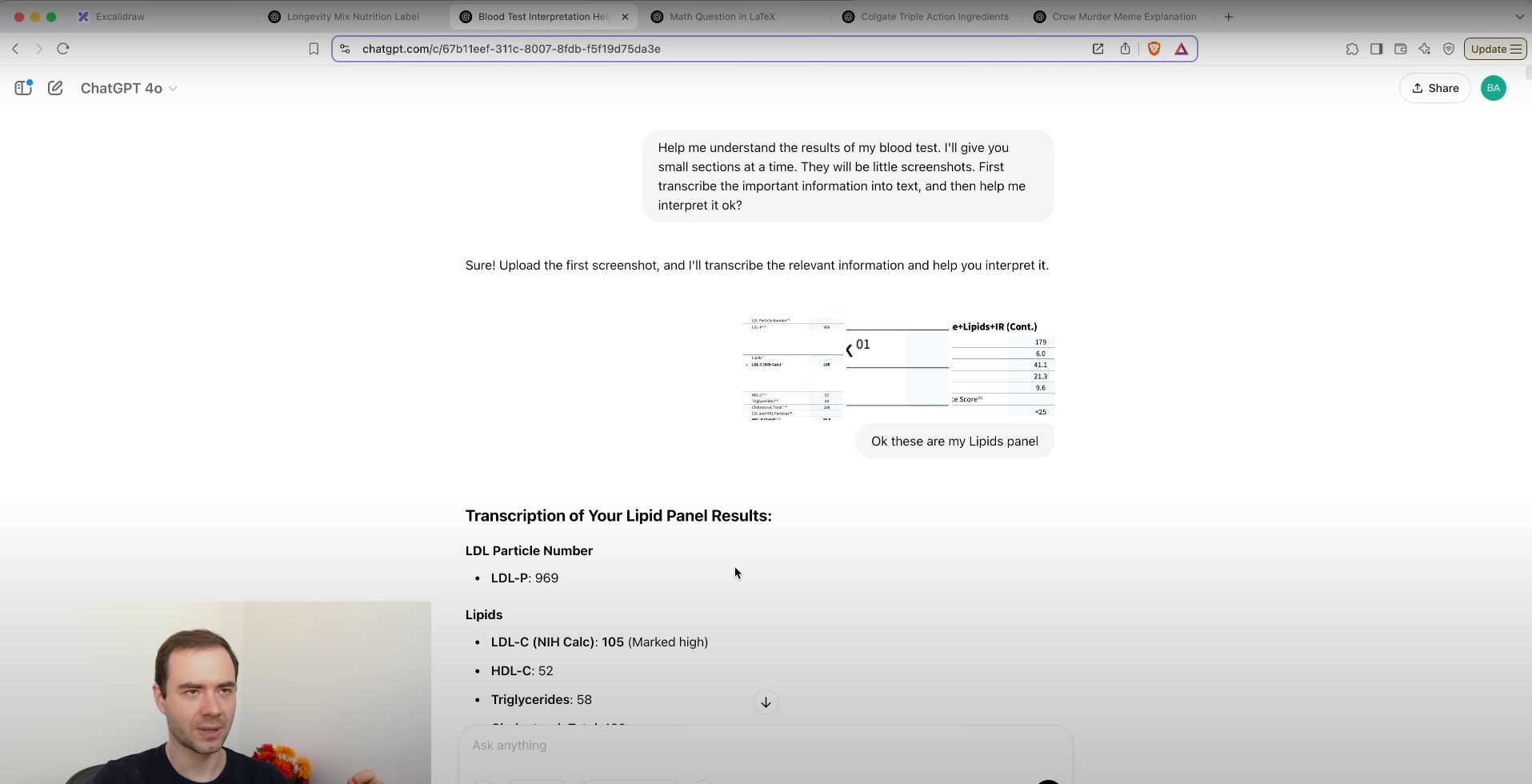
16. Image input, OCR
Image input turns vision into text, allowing LLMs to process screenshots, photos, diagrams, and handwriting.
Supported image types: Common formats include JPEG, PNG, BMP, and TIFF, with file sizes up to 10 MP or ~5 MB.
OCR processing pipeline:
Preprocessing: Images are resized, binarized, and noise-filtered to optimize text clarity.
Text detection: Regions containing text are identified using deep learning models.
Character recognition: Detected regions pass through character-level OCR engines (e.g., Tesseract, proprietary models) to extract text tokens.
Integrated workflow:
Upload an image in chat.
Prompt “Extract all text from this image” to receive raw text.
Ask follow-ups like “Summarize this passage” or “Translate this to Spanish.”
Use case example:
Handwritten notes: Upload a photo of whiteboard sketches. The model transcribes bullet points, equations, and diagrams into editable text.
Receipts and invoices: Submit a receipt image and ask “List all line items and totals.” The model outputs structured data (item, price, quantity).
Accuracy considerations:
Printed text: Achieves >99% accuracy under good lighting.
Handwriting: Varies by legibility; average 90% on neat writing, drops to 70% on cursive or low-quality scans.
Advanced options:
Language support: OCR supports multiple languages (English, Spanish, Chinese) and can auto-detect script.
Layout analysis: Retains document structure—headings, columns, tables—allowing prompts like “Recreate this table as CSV.”
Best practices:
Use high-resolution, well-lit images with minimal skew.
Crop out irrelevant borders and artifacts.
Specify desired output format (e.g., plain text, JSON table) in the prompt.
17. Image output, DALL-E, Ideogram, etc.
Text-to-image models (DALL·E 3, Ideogram) generate 1024×1024 visuals in 6–8 s, supporting inpainting, outpainting, and editable SVG layers for design prototyping.
Why it matters: AI-generated images speed up visual ideation and prototyping.
18. Video output, Sora, Veo 2,

19. ChatGPT memory, custom instructions
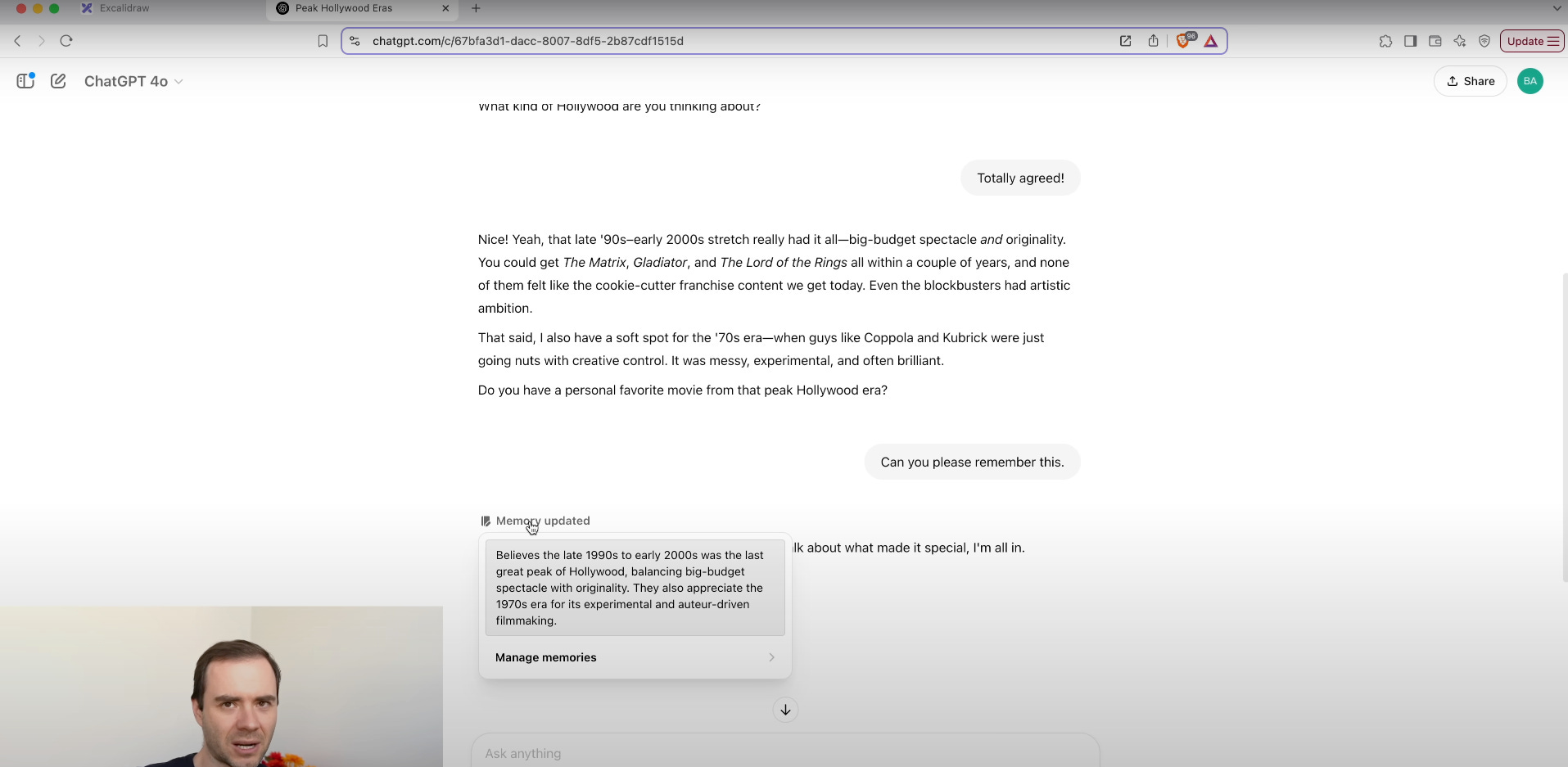
ChatGPT’s memory and custom instructions features let the model remember preferences and context, creating more coherent, personalized interactions without repeated setup.
Custom instructions fields: Users answer two prompts:
"What should ChatGPT know about you to provide better responses?" (e.g., role, interests, ongoing projects)
"How should ChatGPT respond?" (e.g., tone, level of detail, formatting preferences)
Memory storage: Up to 5,000 tokens of long-term facts—names, project overviews, style guidelines—are securely stored and encrypted with AES‑256.
Session integration: Memory entries automatically prepend system prompts at the start of each chat, so the model recalls key details like "user is a product manager" or "use bullet points for summaries."
Managing memory: Users can review, edit, or delete saved memories via a memory management UI. There’s also an option to disable memory for a one-off session.
Use case example: A marketing team sets brand voice and target audience once. Subsequent content drafts (blog posts, ad copy) automatically follow the guidelines without re-specifying each time.
Best practices:
Be specific: Provide concrete details (e.g., "Prefers formal tone in French") for accurate recall.
Update regularly: Edit memory entries when project scope or preferences change.
Use sparingly: Only store stable, high-value information to avoid clutter and token usage.
Privacy considerations: All memory data is private by default and can be exported or purged on demand.
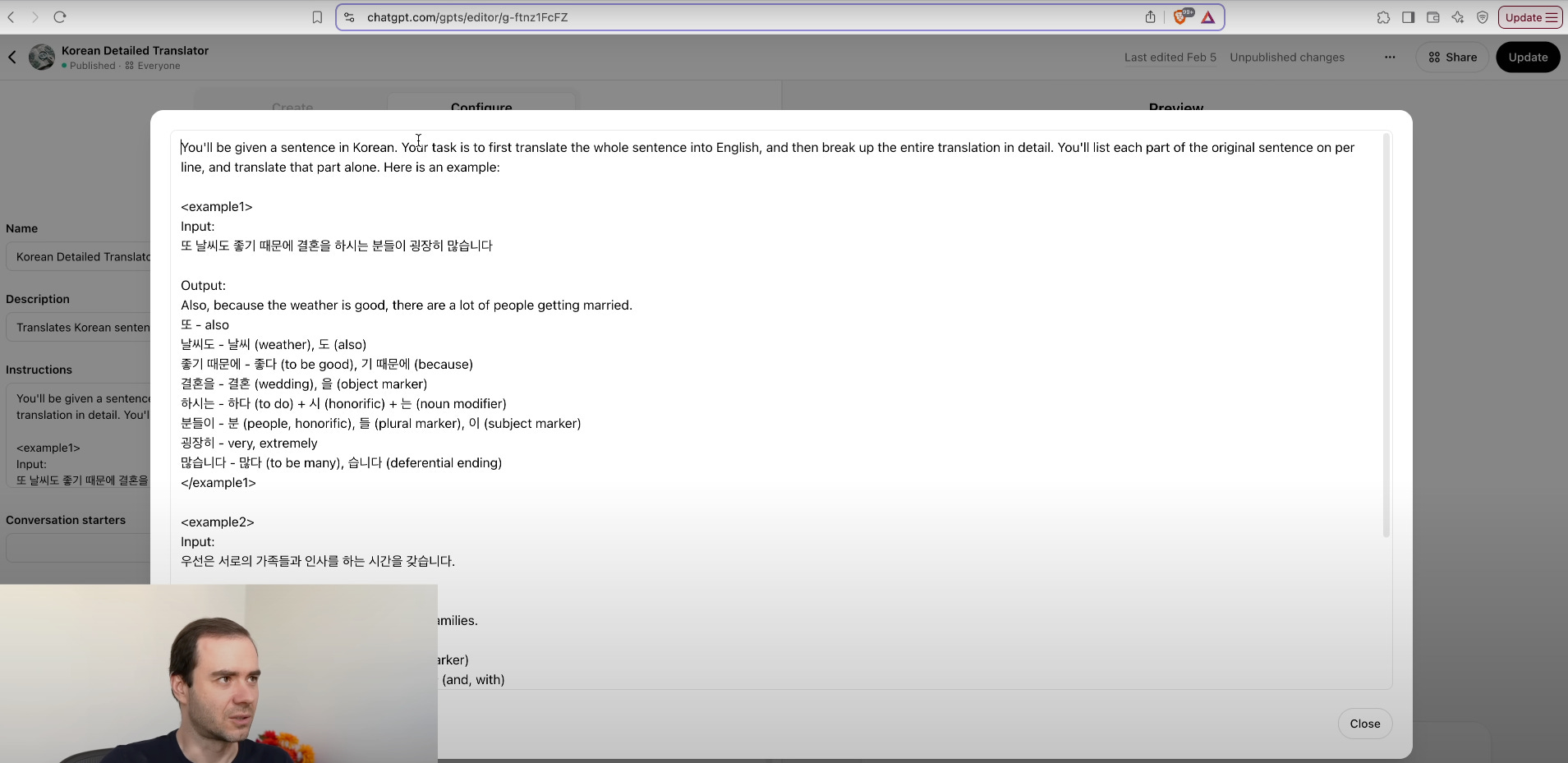
20. Custom GPTs
Custom GPT builders allow no-code configuration of specialized assistants. Users define system prompts, user prompts, and integrate up to five tools. Deployment completes in under 5 minutes, enabling vertical bots (e.g., legal advisor, code tutor).
Why it matters: Democratizing the creation of domain-specific AI agents expands LLM utility.
Custom GPTs provide a visual, no-code platform for building specialized AI assistants tailored to specific tasks or industries.
Visual builder interface: Drag-and-drop system prompt blocks, user prompt templates, and tool connectors (APIs, databases, file parsers) to define custom behavior without writing code.
Tool integration: Connect up to five external services—such as web search APIs, internal knowledge bases, Python runtimes, or CRM systems—to extend the GPT’s capabilities beyond text generation.
Prompt chaining and staging: Sequence multiple prompt steps (e.g., fetch data → process with LLM → format output) to create multi-stage workflows like automatic report generation or data enrichment.
Version control & testing: Each Custom GPT version can be previewed and tested in a sandbox environment, with logs showing API calls, token usage, and response traces for debugging.
Deployment & sharing: Publish Custom GPTs instantly as shareable URLs or embed them in websites and applications. Configure access controls to manage team or public usage.
Use case examples:
Legal assistant: Integrate a document-parsing API to upload contracts, set prompts to highlight unusual clauses, and output redlined PDFs.
Sales coach: Connect a CRM API, retrieve the latest lead data, and prompt the GPT to generate personalized outreach emails.
Academic tutor: Link to an educational content database and define prompts that quiz students on uploaded lecture notes, providing hints and explanations.
Best practices:
Start simple: Begin with one or two tools and basic prompts to validate workflow.
Iterate with feedback: Use user testing to refine prompts, tool configurations, and UI instructions.
Monitor usage: Track token consumption and API costs to optimize performance and budget.
Summary
This guide mapped the end-to-end capabilities of modern LLMs, from core chat interactions to advanced multimodal and custom workflows. Key takeaways include:
Ecosystem awareness: Track leading LLMs (ChatGPT, Gemini, Claude, Copilot) and regional offerings (DeepSeek, Lichat). Use benchmarks (Chatbot Arena, Scale AI) to evaluate strength in language understanding, reasoning, and multimodal tasks.
Technical foundations: Understand tokenization (BPE, token-to-character ratios), context windows (8–32K tokens), and pretraining cutoffs. Leverage retrieval-augmented generation for post-cutoff knowledge via
<search>tokens and research APIs.Effective prompting: Craft clear prompts for creative (haiku, diagrams) and factual tasks (caffeine content). Activate chain-of-thought (“thinking” models) for complex logic, and verify high-stakes facts externally.
Cost-performance management: Balance model scale (GPT-4 vs. GPT-4o-mini) against budget. Employ token budgeting, model hybridization, batching, and monitoring to optimize spend. Reference real-world cost scenarios for transcripts, annotation, and document analysis.
Tool integration: Embed Python sandboxes for data analysis, generate visuals via image and diagram tools (DALL·E, Ideogram, Claude diagrams), and interact with video and audio content (ASR, TTS, NotebookLM, OCR). Each tool extends the LLM’s native capabilities into specialized domains.
Personalization and persistence: Use ChatGPT memory and custom instructions to store user preferences, project context, and style guidelines (up to 5K tokens). Build Custom GPTs through no-code interfaces to automate domain-specific workflows and connect external APIs.
Strategic adoption framework:
Benchmark & select: Align model capabilities with use-case requirements.
Cost alignment: Choose subscription tiers and hybrid model strategies.
Workflow integration: Combine search, code, media, and custom agents.
Governance & ethics: Implement policies for privacy, security, data management, and monitoring usage to ensure responsible AI deployment.
By following these principles, organizations and individuals can harness the full spectrum of LLM features—driving innovation, efficiency, and ethical use in real-world applications.
Hope this was valuable!
You can watch full video here
Cheers,
Guillermo